def get_crags_from_reg(url):
classes = ['name', 'routes']
df = pd.DataFrame(columns=['name', 'Sport', 'routes', 'url', 'lat', 'long'])
soup = get_soup(url)
crags = soup.find_all("div", {"class": "area"})
for i, crag in enumerate(crags):
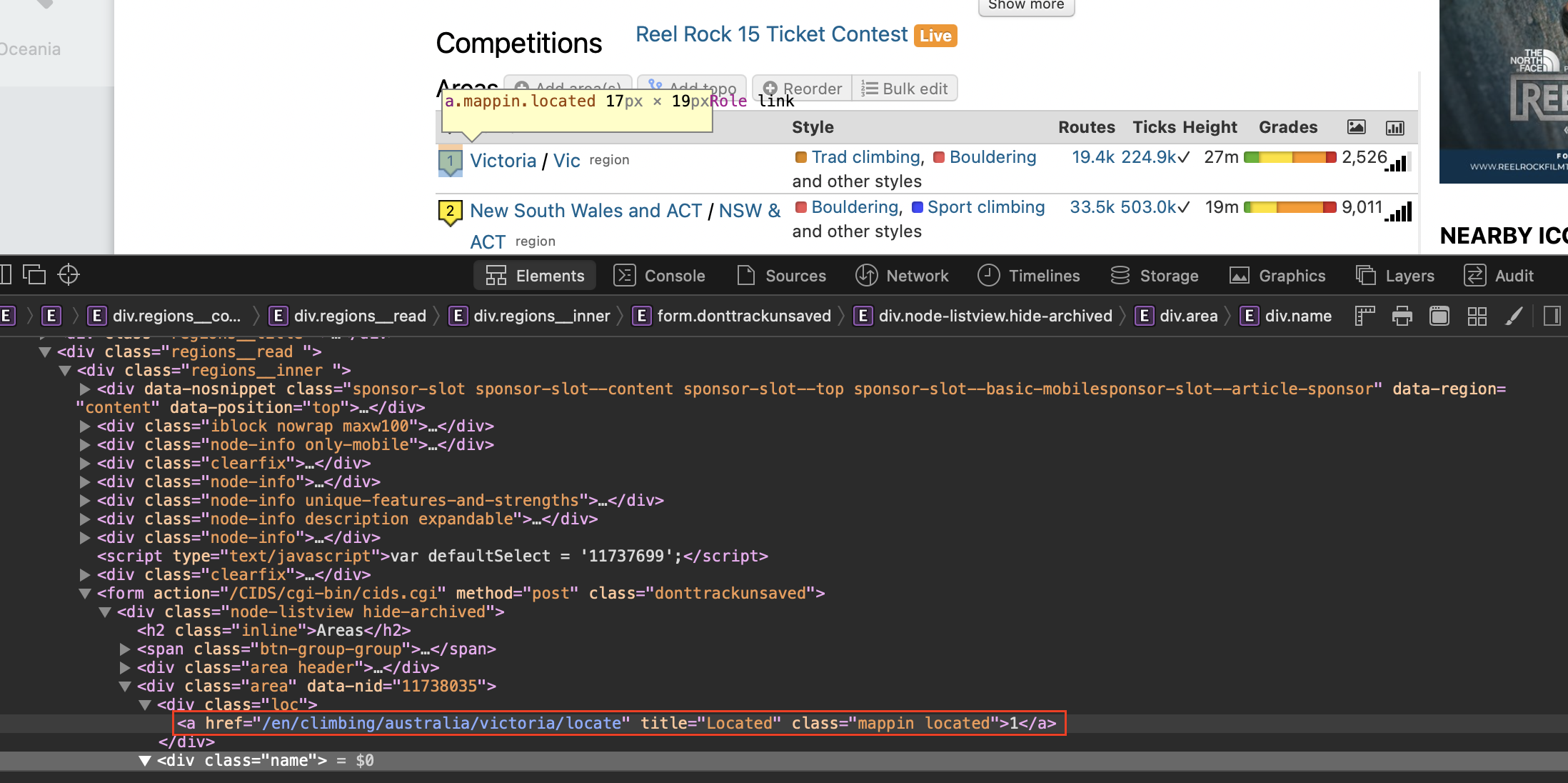
a = crag.find('div', {"class": "loc"})
try:
link = a.find('a', {"class": "mappin located"})['href']
except TypeError:
continue
full_link = f'https://www.thecrag.com{link}'
guide = urljoin(full_link, 'guide')
lat_long = get_lat_long(guide)
df.loc[i, 'lat'] = lat_long[0]
df.loc[i, 'long'] = lat_long[1]
df.loc[i, 'Sport'] = 'Climbing'
df.loc[i, 'url'] = urljoin(full_link, ' ').strip()
for cls in classes:
df.loc[i, cls] = crag.find('div', {"class": cls}).text
df.routes = df['routes'].str.replace(',', '')
df = df.dropna()
df = df.astype({'name': str, 'Sport': str, 'routes': int, 'url': str, 'lat': float, 'long': float})
return df